
실시간 뉴스
- [TVis] 심형래, 안면거상 후 근황…”’영구’ 본모습 보여주고 싶어서” (데이앤나잇)
- [단독] 김광진 “‘불후’ 정글에 뛰어든 느낌…우즈와 듀엣 우승 큰 의미” [IS인터뷰]
- [2026 밀라노] 세계가 주목한 차준환, 첫 경기서 ‘점프 미스’ 후 아쉬움…“평소 하던 실수는 아냐, 만회할 거”
- [2026 밀라노] ‘SNS 팔로워 214만’ 올림픽 출전 선수 수입 1위 中 스타, 1차 실패 딛고 결선행
- [2026 밀라노] 패패패패패→‘승’ 한국 믹스더블, 연장 혈투 끝에 미국 제압하고 대회 첫 승리
- [2026 밀라노] ‘아 트리플 악셀’ 차준환, 팀 이벤트 쇼트프로그램서 8위…결선 좌절
- [2026 밀라노] 포상금 3억원 주인공 떴다…이탈리아 빙속 베테랑, 자신의 생일에 올림픽 신기록·대표팀 1호 금메달 겹경사
- 신인 박여름이 팀 내 최고 득점, 8연패 최하위 정관장의 마지막 희망
- [2026 밀라노] 한국 컬링 믹스더블, 체코에 밀려 라운드로빈 5연패…단독 최하위
- “그런 관심 필요 없어” 스키점프 ‘성기 확대’ 논란→선수 반응은 냉담 [2026 밀라노]




올해 가속 페달을 밟는 네이버의 AI(인공지능) 비전이 예상치 못한 암초를 만났다. 생성형 AI 검색의 밑거름인 뉴스 콘텐츠 무단 학습 논란에 휩싸이며, 언론사와의 갈등 봉합 과제를 떠안았다. 해외에서도 아직 마련되지 않은 대가 기준을 네이버가 선제적으로 수립할지 관심이 쏠린다.
네이버, 지금도 뉴스로 AI 학습?
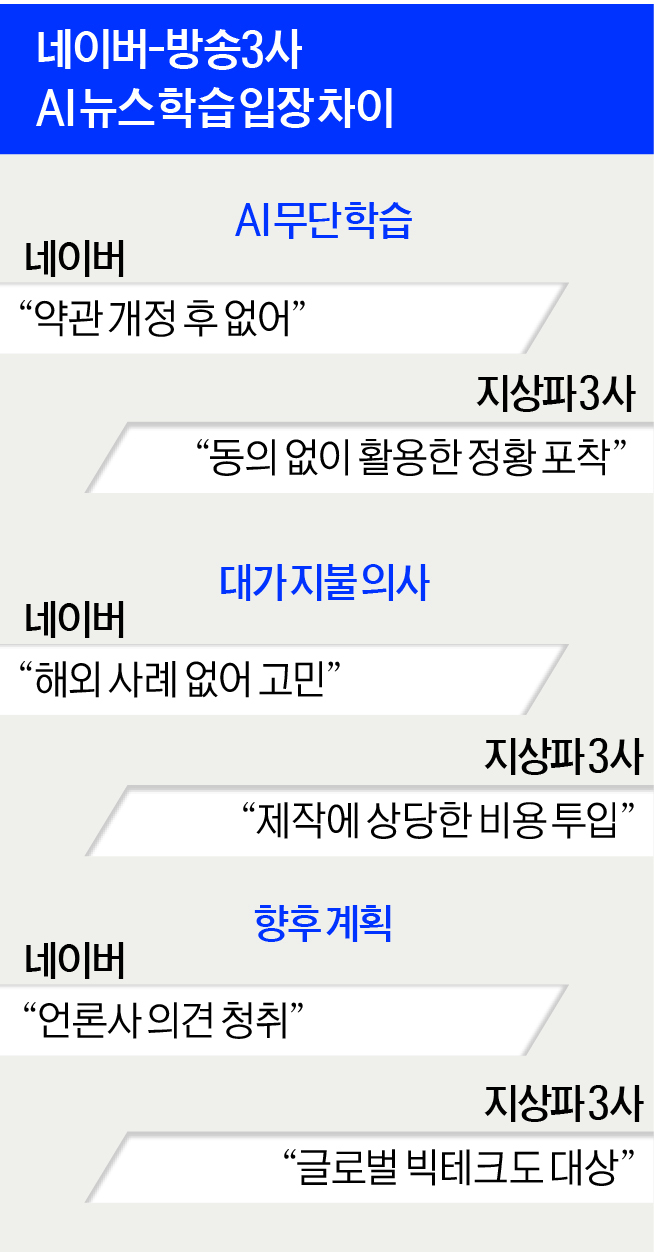
KBS·MBC·SBS 지상파 방송 3사는 지난 13일 '하이퍼클로바X' 등 생성형 AI 학습에 자사 콘텐츠를 활용한 네이버를 상대로 저작권 침해 및 부정경쟁방지법 위반으로 인한 손해배상 청구와 학습 금지 등을 청구하는 내용의 소송을 제기했다고 22일 밝혔다. 국내 언론사가 뉴스 콘텐츠 무단 이용을 두고 기업에 소송을 건 것은 이번이 처음이다.
지상파 방송을 대변하는 한국방송협회 관계자는 "AI 학습 이용 데이터의 출처와 내용, 데이터 취득 경로 등의 공개를 요청했지만 네이버가 이를 받아들이지 않았다"며 "AI 서비스를 써보니 뉴스 데이터를 학습하고 있는 정황이 포착됐다"고 말했다.
네이버는 과거 적법한 절차를 거쳐 AI 학습에 CP(콘텐츠 제휴) 계약을 맺은 언론사의 뉴스 데이터를 활용했었다.
이후 생성형 AI가 화두로 떠오르면서 언론사가 문제 제기를 하자 뉴스 약관을 개정해 지난 2023년 6월부터 동의 없이 뉴스 데이터를 사용하지 않고 있다는 입장이다. 하지만 방송협회 관계자는 "사실이 아닌 것으로 보인다"고 반박했다.

지상파 3사에 따르면 네이버의 대화형 AI 서비스 '클로바X'는 2023년 6월 이후 보도된 기사도 답변에 녹이고 있다.
지난 16일 한 지상파 방송이 경주의 유네스코 세계문화유산 경주대릉원이 인근 카페에 의해 훼손됐다는 내용을 단독 보도했는데, 클로바X에 '경주의 세계문화유산이 훼손된 사례가 있나'라고 물었더니 해당 기사의 요약을 제공했다.
정보의 출처를 묻자 한 뉴스 통신사와 문화재청의 링크를 보여줬는데, 막상 접근해 보니 존재하지 않는 페이지로 연결됐다.
경주대릉원 훼손 기사는 다른 언론사에서는 다루지 않은 만큼 클로바X가 지상파 뉴스 데이터를 기반으로 답변했을 가능성이 크다.
"현재는 뉴스 데이터를 AI 학습에 쓰지 않는다"고 설명한 네이버 관계자는 "방송협회가 제기한 소송은 보도로 확인했을 뿐 아직 소송 내용을 접하지 못한 사항으로 세부 내용 파악 후 필요한 입장을 밝힐 수 있을 것"이라고 말했다. 이날까지도 네이버에 소장은 전달되지 않은 것으로 알려졌다.
해외서도 대가 두고 갈등
해외에서도 오픈AI가 운영하는 챗GPT 등 생성형 AI의 뉴스 데이터 학습 문제는 쉽게 풀리지 않는 과제로 남아있다.
지난해 10월 미국 월스트리트저널의 모회사 다우존스와 뉴욕포스트는 AI 검색 서비스를 제공하는 퍼플렉시티가 기사와 사설, 기고문 등을 불법적으로 재생산한다고 보고 저작권 및 상표권 침해 소송을 제기했다.
이 외에도 뉴욕타임스와 시카고 트리뷴 등 현지 유력 언론사가 오픈AI와 마이크로소프트 등을 상대로 비슷한 이유로 소송을 진행 중이다.
언론계는 영상 콘텐츠를 주로 제작하는 지상파의 이번 소송이 최종적으로는 유튜브 등 빅테크를 겨냥한 것으로 조심스럽게 보고 있다.
방송협회 관계자 역시 "일단 뉴스 콘텐츠를 활용한 사례 위주로 살펴보고 있다"며 "당연히 방송 콘텐츠를 불법적으로 이용한 사실이 확인되면 순차적으로 대응할 계획"이라고 말했다.
다만 생성형 AI의 뉴스 데이터 학습과 관련해 참고할 만한 글로벌 스탠더드(국제 표준)가 마련되지 않았고, 언론사끼리도 의견이 엇갈릴 수 있어 실타래를 풀기까지는 적지 않은 시간이 걸릴 전망이다.
한 플랫폼 업계 관계자는 "AI에 기사를 제공할 정도의 위상으로 만족하는 언론사도 있을 테고, 대가를 지급한다고 해도 원하는 수준이 서로 다를 것이라 계약으로 쉽게 풀 수 없는 문제"라고 말했다.
정길준 기자 kjkj@edaily.co.kr
당신이 좋아할 만한정보
AD
당신이 좋아할 만한뉴스



![인도, 글로벌 저가 제네릭에서 바이오 허브로 탈바꿈[제약·바이오 해외토픽]](https://image.edaily.co.kr/images/Photo/files/NP/S/2026/02/PS26020700379T.jpg)


지금 뜨고 있는뉴스





행사&비즈니스


많이 본뉴스
![[포토] 인사말 하는 에이티즈 종호](https://image.isplus.com/data/isp/image/2026/02/05/isp20260205000460.400x280.0.jpg)
![[포토] 인사말 하는 에이티즈 민기](https://image.isplus.com/data/isp/image/2026/02/05/isp20260205000461.400x280.0.jpg)
![[포토] 인사말 하는 에이티즈 홍중](https://image.isplus.com/data/isp/image/2026/02/05/isp20260205000459.400x280.0.jpg)
![[포토] 인사말 하는 에이티즈 우영](https://image.isplus.com/data/isp/image/2026/02/05/isp20260205000458.400x280.0.jpg)
![[포토] 에이티즈 산, 그렇게 쳐다보면 형 또 설레](https://image.isplus.com/data/isp/image/2026/02/05/isp20260205000457.400x280.0.jpg)
![[포토] 인사말 하는 에이티즈 여상](https://image.isplus.com/data/isp/image/2026/02/05/isp20260205000456.400x280.0.jpg)
![[포토] 인사말 하는 에이티즈 윤호](https://image.isplus.com/data/isp/image/2026/02/05/isp20260205000455.400x280.0.jpg)
![[포토] 인사말 하는 에이티즈 성화](https://image.isplus.com/data/isp/image/2026/02/05/isp20260205000454.400x280.0.jpg)
![[포토] 에이티즈 종호, 쌍 엄지척](https://image.isplus.com/data/isp/image/2026/02/05/isp20260205000448.400x280.0.jpg)
![[포토] 에이티즈 종호, 곰돌이의 손하트](https://image.isplus.com/data/isp/image/2026/02/05/isp20260205000446.400x280.0.jpg)
![[포토] 에이티즈 종호, '명창 하리보'의 당당함](https://image.isplus.com/data/isp/image/2026/02/05/isp20260205000447.400x280.0.jpg)
![[포토] 에이티즈 우영, 프린스의 맥박 짚기](https://image.isplus.com/data/isp/image/2026/02/05/isp20260205000444.400x280.0.jpg)